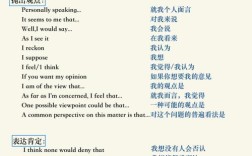
口语评测技术近年来在教育、语言培训等领域得到了广泛应用,旨在通过人工智能算法对学习者的发音、流利度、语法等维度进行自动化评估,并提供即时反馈,尽管技术不断迭代,口语评测在实际应用中仍面临诸多挑战,甚至被部分用户和专家视为“失败”,这种“失败”并非指技术完全无效,而是指其当前能力与用户期待、实际需求之间存在巨大差距,导致评测结果难以真正反映口语水平,甚至可能误导学习者,以下从多个维度分析口语评测失败的原因。

评测维度的局限性导致评估结果片面,口语能力是一个复杂的综合体系,包含发音、语调、流利度、词汇运用、语法准确性、逻辑连贯性、甚至文化语境理解等多个层面,目前的口语评测技术主要依赖语音识别(ASR)和自然语言处理(NLP)算法,能够精准量化的是发音准确度、语调匹配度、语速、停顿频率等“物理特征”,但对于更深层次的“语言能力”则力不从心,算法可以判断“apple”的发音是否接近标准音,但无法识别学习者用“apple”表达“苹果”还是“苹果公司”时的语境合理性;能够检测语法错误(如主谓不一致),却难以评估句子之间的逻辑衔接是否自然,这种“重形式轻内容”的评估方式,容易让学习者陷入“发音标准即口语好”的误区,而忽略语言的实际交际功能,一项针对国内主流口语评测软件的测试显示,当用户用语法正确但逻辑混乱的句子回答问题时,系统仍可能给出高分,这显然与真实口语能力评估的目标背道而驰。
算法的“文化盲区”与“语境缺失”使其难以适应真实交际场景,语言是文化的载体,口语表达中包含大量隐性的文化背景、语气暗示和社交礼仪,在英语中,“Could you possibly...”比“Can you...”更委婉,这种语气的细微差别在口语评测中往往被忽略,因为算法无法理解“礼貌程度”与语言形式之间的关联,再比如,中文里的“哪里哪里”作为谦虚回应,若直译为“Where where”会被视为语法错误,但算法可能无法识别其作为文化谦辞的特殊性,口语评测的场景通常是预设的、孤立的(如“请描述你的家乡”),而真实交际中,对话是动态的、互动的,需要根据对方反馈及时调整内容,算法无法模拟这种互动性,导致评测结果与真实口语应用场景脱节,学习者可能在评测中背诵了完美的自我介绍,但在实际对话中却因无法理解对方问题而卡壳,这种“高分低能”的现象进一步加剧了口语评测的失败形象。
第三,对“标准口音”的过度强调扼杀语言多样性,打击学习者信心,大多数口语评测系统以“标准音”(如普通话的普通话水平测试标准、英语的通用美音/英音)作为唯一评判基准,对带有地域口音或个人特色的发音给予低分,这种做法忽视了语言的多样性——口音本身并非错误,而是语言地域变体的体现,一位来自四川的学习者说普通话时带有“川普”口音,可能因发音不“标准”而被扣分,尽管其表达清晰、逻辑完整;一位印度人说英语时带有“咖喱味”,其语法和用词可能完全正确,却因口音问题被判定为“发音不达标”,这种“一刀切”的评判标准不仅不科学,还可能打击学习者的积极性,让他们因害怕“口音不标准”而不敢开口,最终陷入“越怕错越不敢说,越不敢说越错”的恶性循环,在真实的国际交流中,沟通的有效性远比口音的“纯正度”更重要,而口语评测系统显然未能传递这一核心价值。
第四,技术依赖导致“应试化”学习,背离语言学习本质,口语评测的广泛应用催生了“应试技巧”的泛滥——学习者不再专注于提升实际口语能力,而是研究如何“讨好”算法,有培训机构总结出“三秒停顿法则”(每句话停顿三秒以匹配算法对“流利度”的判定)、“关键词重复策略”(重复题目中的关键词以提高词汇匹配度)等“应试套路”,这种“为评测而学习”的方式,让口语训练变成了机械的“算法博弈”,学习者可能通过反复练习特定题目获得高分,但一旦面对真实场景中的新话题,依然无法有效沟通,更严重的是,部分学习者为了追求“发音标准”,刻意模仿录音中的语调,失去了个人的语言风格,导致口语表达生硬、缺乏自然感,这种“应试化”倾向与语言学习的初衷——即培养真实的交际能力——完全背道而驰,使得口语评测沦为“形式主义”的工具。

数据偏差与隐私风险进一步削弱了评测的可信度,口语评测系统的算法依赖于大量标注数据,而数据来源的单一性可能导致评估偏差,如果训练数据主要来自母语者或高水平学习者,那么对初级学习者的评估就可能存在“严苛偏差”;反之,若数据中包含大量错误表达但未被标注,系统可能将错误视为“正确”,语音数据涉及个人隐私,部分平台在数据收集和使用过程中缺乏透明度,甚至存在数据泄露的风险,当学习者发现自己的语音数据被用于商业用途或算法训练时,对评测系统的信任度自然会降低,这种技术层面的缺陷,加上隐私保护的缺失,让口语评测的“公正性”和“安全性”备受质疑。
口语评测的“失败”并非技术本身的失败,而是其设计理念、技术实现与应用场景之间的错位,当前的技术难以全面、准确地评估口语能力的复杂性,过度依赖算法、忽视语言本质,不仅无法有效帮助学习者提升真实交际能力,还可能带来负面影响,口语评测若要真正“成功”,需要在算法层面融入更多语境理解、文化包容和动态交互能力,同时回归语言学习的本质——即以沟通为核心,而非以分数为导向,只有当评测系统能够模拟真实交际场景、尊重语言多样性,并真正服务于学习者的能力提升时,才能摆脱“失败”的标签,成为语言学习的有效工具。
相关问答FAQs
Q1:口语评测系统为什么总是对带有口音的发音打低分?
A1:这主要源于口语评测系统的算法设计逻辑,大多数系统以“标准音”(如普通话的普通话水平测试标准、英语的通用美音/英音)作为训练基准,通过对比学习者的发音与标准音的声学特征(如音高、音长、频谱)来判定准确度,当学习者带有地域口音或母语迁移口音时,其发音特征与标准音存在差异,算法会将其识别为“偏差”并扣分,系统缺乏对“口音多样性”的包容性训练,无法区分“口音”与“发音错误”——印度英语的“卷舌音”特征在算法看来可能是“发音不标准”,但实际上是语言变体的正常表现,要解决这个问题,未来系统需要引入更多元的口音数据,并建立“发音可懂性优先于口音纯正度”的评估标准。

Q2:使用口语评测系统学习口语,真的能提升实际交际能力吗?
A2:当前大多数口语评测系统对实际交际能力的提升作用有限,甚至可能产生负面影响,系统侧重于发音、语法等“形式维度”的评估,而忽略了逻辑表达、语境适应、互动回应等“交际维度”,导致学习者可能“发音流利但无法有效沟通”,系统的“应试化”倾向会让学习者陷入“套路练习”,例如通过背诵固定答案、刻意模仿语调来获得高分,但这种能力无法迁移到真实对话场景,真正的口语能力提升需要大量互动实践(如与真人对话、小组讨论)和真实语境的反馈,而口语评测系统仅能提供机械化的单方面评估,难以替代真实交际环境,建议将口语评测作为辅助工具(如纠正发音错误),而非主要学习手段,同时注重增加真实对话练习。